学习还是自我对齐 ? 关于指令微调的内在机制的探究
论文标题:Learning or Self-aligning? Rethinking Instruction Fine-tuning.
指令微调(Instruction Fine-tuning,IFT)已经成为大型语言模型构建的核心步骤之一,然而关于IFT对大模型的输出的影响机制的深入分析仍然非常缺乏。当前应用指令微调的工作主要有两个目的,模型行为模式的转换和注入特定领域的知识。由于缺乏对指令微调的深入分析,我们很难理解指令微调给模型带来的增益究竟是由于其成功地对齐了我们期望的输出空间,实现了更好的知识表达机制,还是由于指令微调过程中确实带来了额外的领域知识增益。
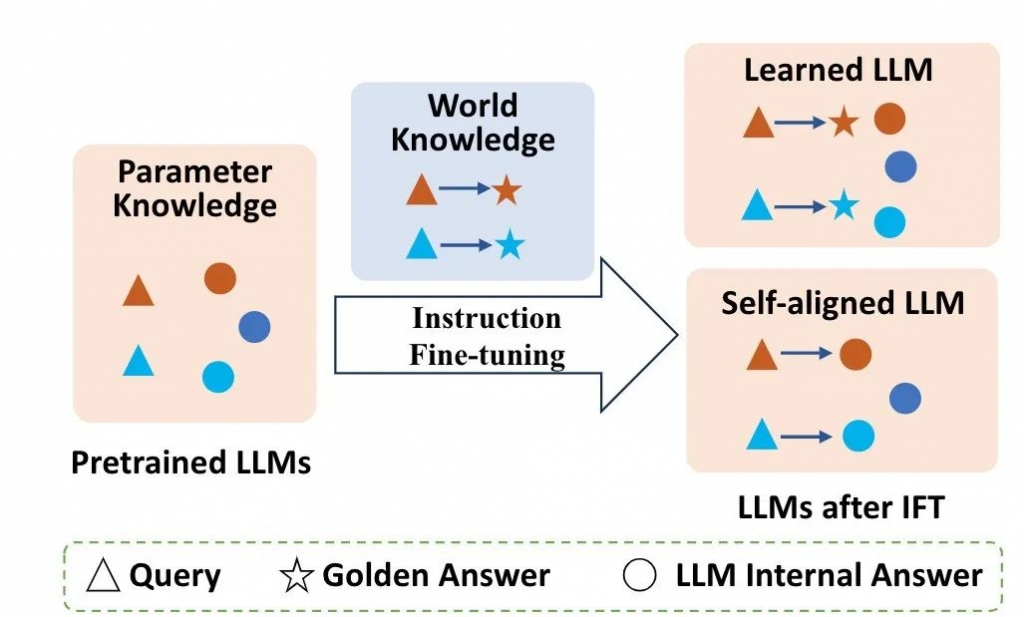
基于知识扰动的分析框架
Harmonious 由与模型参数知识一致的指令数据组成,是基座模型可以在少样本上下文学习下正确回答的问题。在该设置下的学习过程中,模型只需要学习行为模式,而不需要学习额外的世界知识; Incompatible 包含了基座模型在少样本上下文学习中无法正确回答的问题。由于与模型参数知识完全不一致,模型在训练阶段既需要学习行为模式,也需要学习世界知识; Self-aligning 该设置下的指令输入与incompatible设置中的完全一致,但是作者将每个指令对应的答案 修改为 基座模型自己预测的答案,以与模型参数知识保持一致。因此,在这种设置下,所有的响应都是不正确的,模型无法学习任何额外的世界知识。
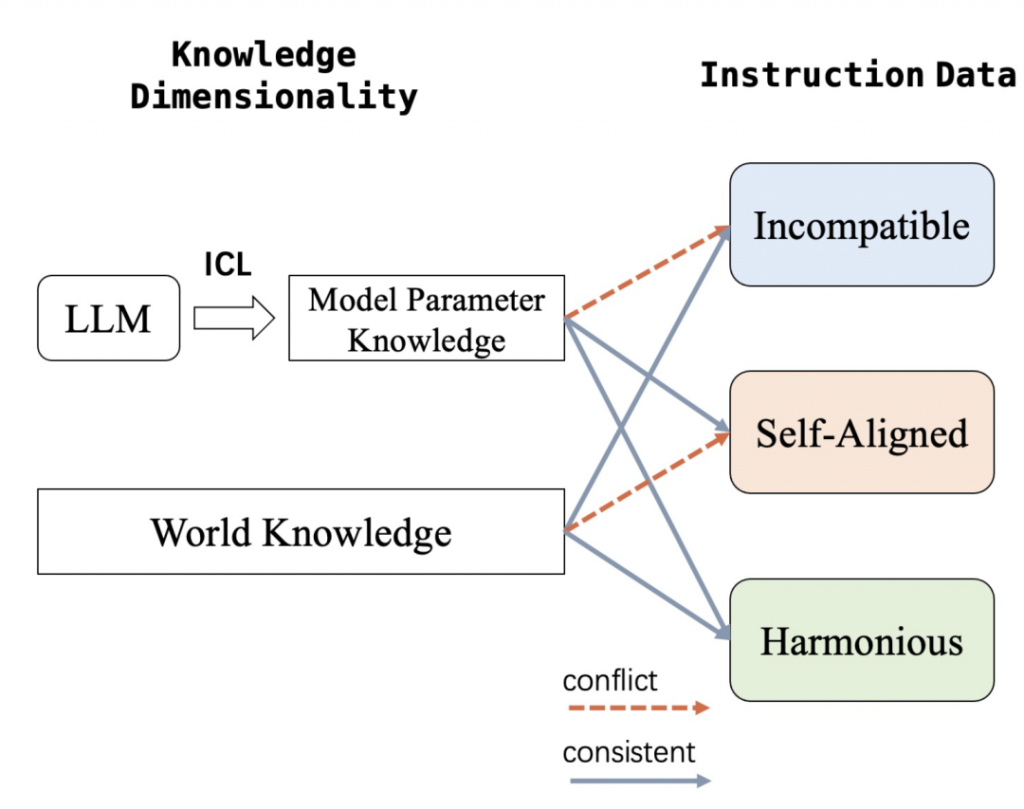
通过控制指令数据所蕴含的知识与模型参数知识的一致性程度,观察使用不同一致性程度的数据微调的模型的行为差异,作者希望回答以下两个研究问题:
- RQ1 指令数据中提供的额外世界知识是如何影响大模型的?
- RQ2 上述影响的潜在原因是什么?
为了回答上述的RQ并进行全面的评估,对于每个领域,作者构建了三种类型的测试集:
- 同质测试集(HOMO),从该领域的训练集所在的数据集留出
- 域内测试集(ID),包含了MMLU中所有属于该领域的subcategories
域外测试集(OOD),包含了MMLU中所有不属于该领域的subcategories
实验
Exp-I: 在IFT中学习额外的知识是否重要?
对于每个领域和基座模型的组合,作者分别构建了上述三组指令数据,并用来微调对应的基座模型,结果如下表所示,harmonious设置(HAR)与self-aligning设置(SELF)在四个基座模型、四个领域的三类评估上基本都明显强于incompatible设置(INC)。
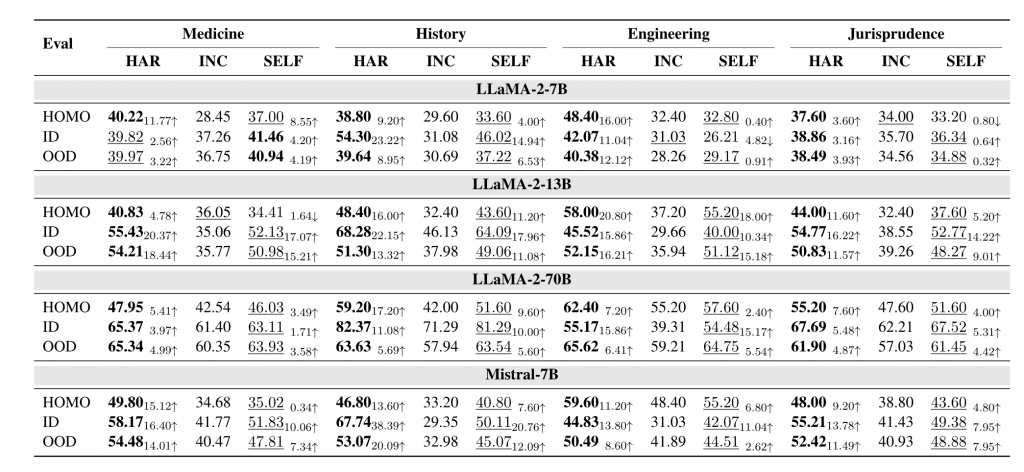
对于IFT而言,学习指令数据中包含有的额外的世界知识很可能并不能够带来增益。
Exp-II: 在IFT上下文中引入额外的世界知识的对比
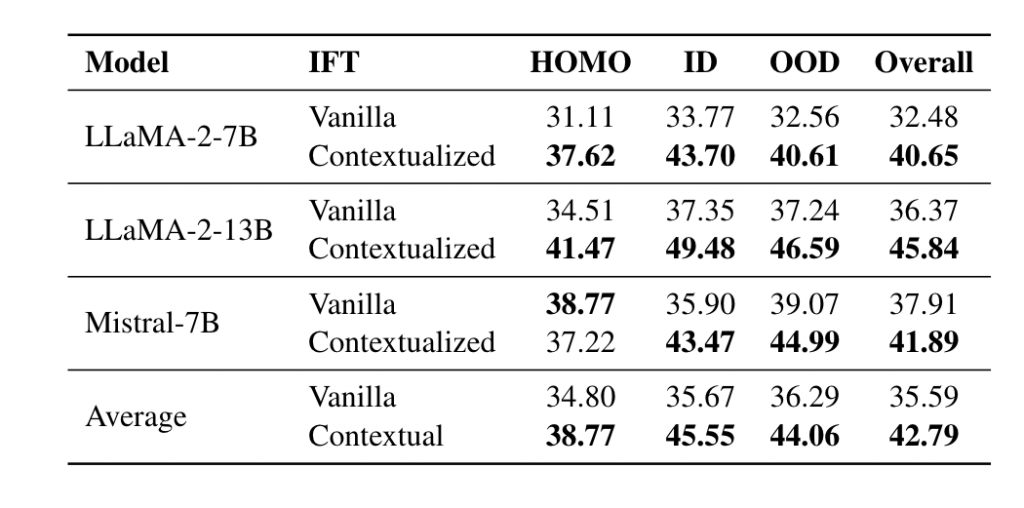
Conclusion1. 对于指令微调而言,学习与模型参数知识不一致的世界知识无法带来增益,甚至会造成额外的损害。
Exp-III: 一致性代表一切吗?
上述发现似乎可以得出一个结论:为了更好地进行行为模式转换,应该使用与模型参数知识完全一致的IFT数据,而不需要任何额外的世界知识。
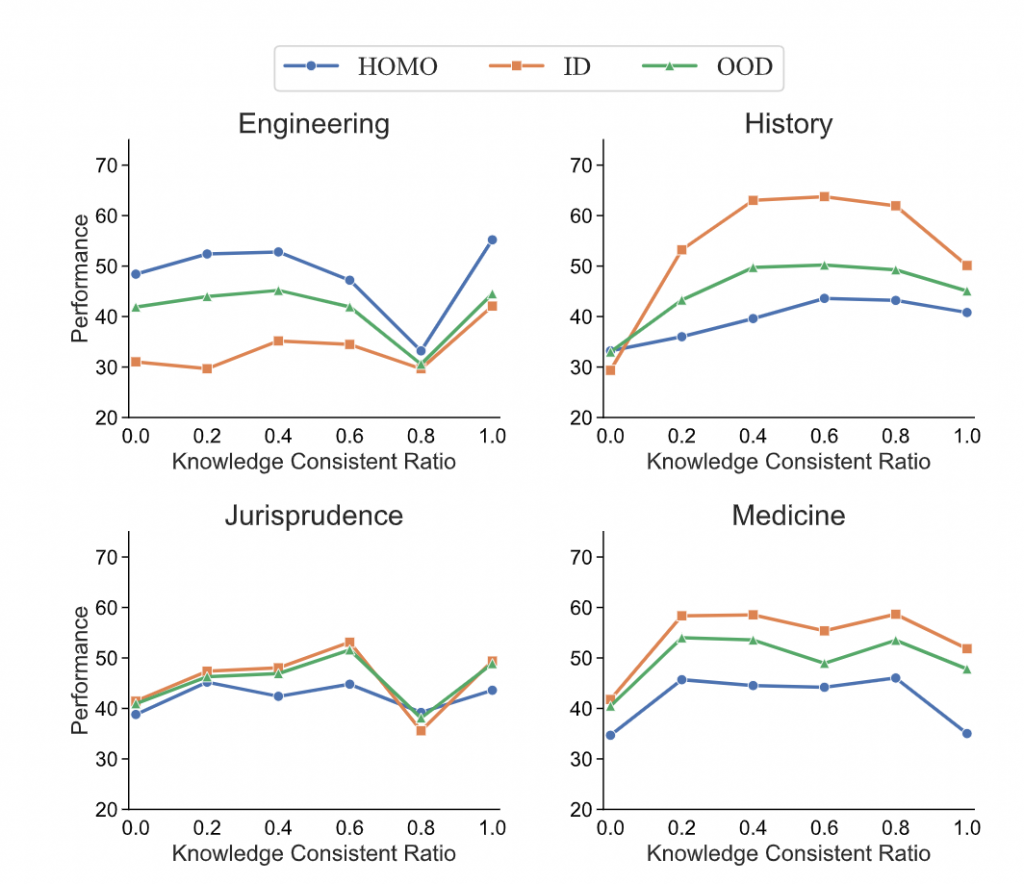
Exp-IV: 对IFT而言,什么是真正重要的?
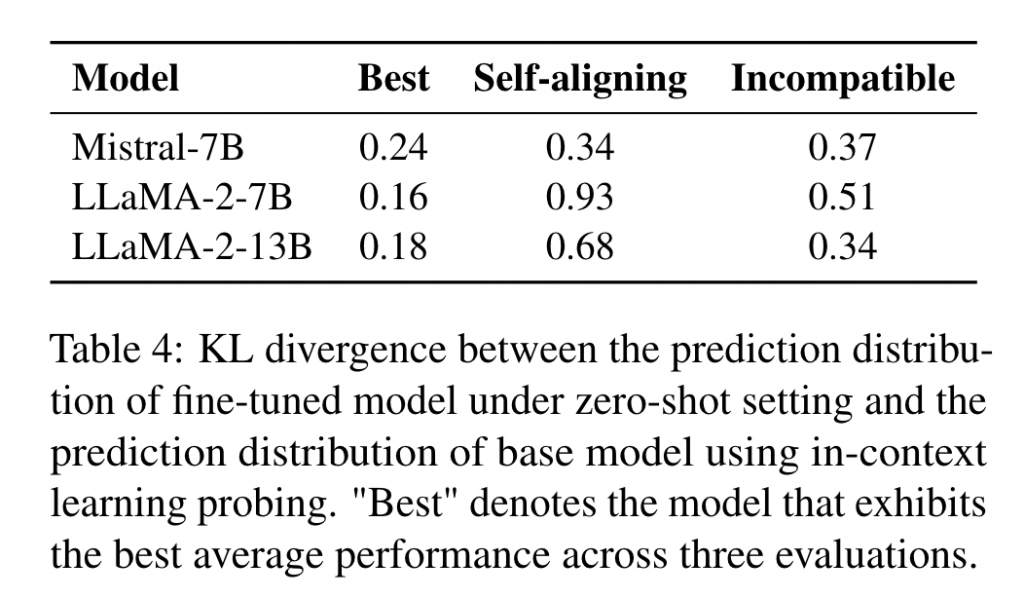
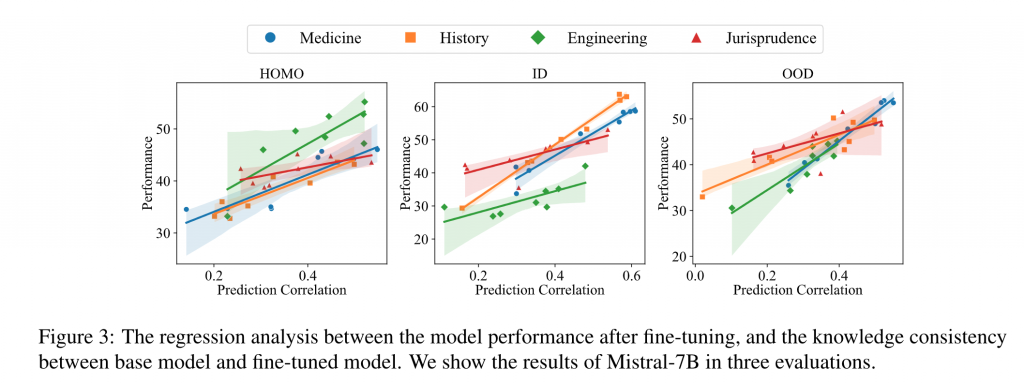
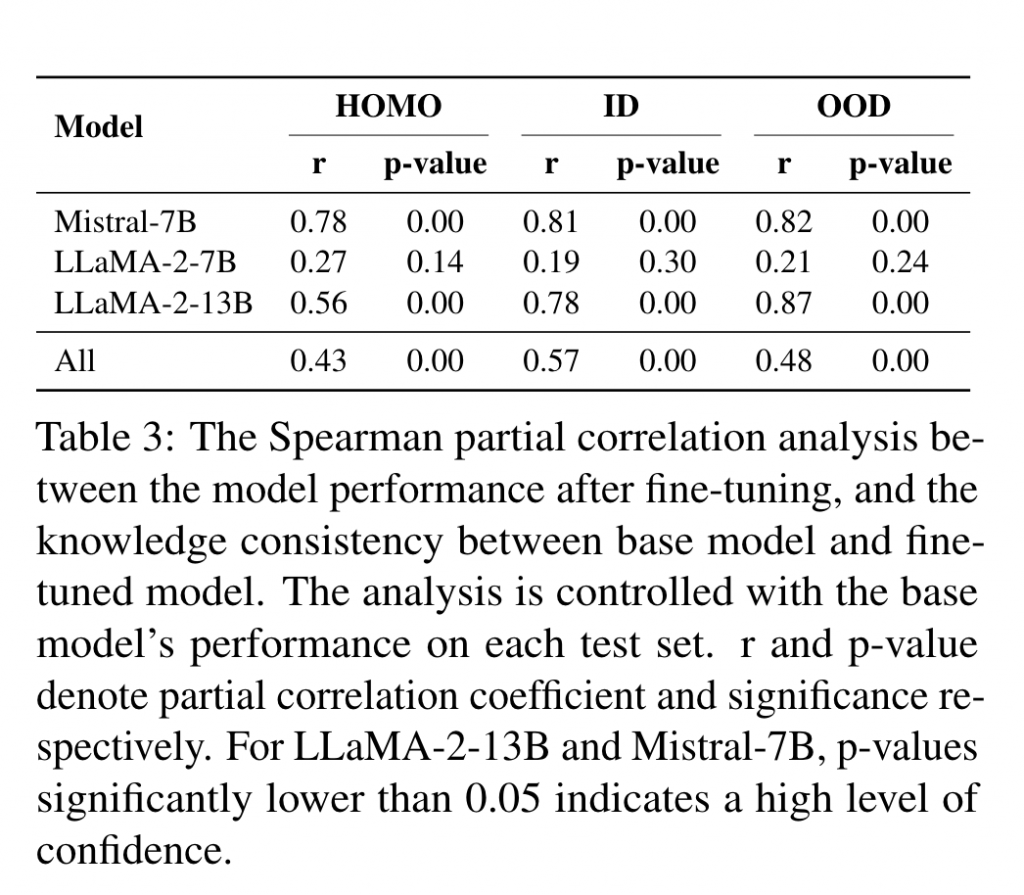
Conclusion 2. 有效指令微调的本质在于完成行为模式转换的同时,保持指令微调前后模型参数知识的一致性。
总结与讨论
指令微调不是一个监督的领域特定知识学习的过程,而是将指令与模型现有参数知识进行一种自我对齐的过程。
引用
[1] Yining Chen, Adrien Ecoffet, Manas Joglekar, Jan Leike, Ilya Sutskever, and Jeff Wu. 2023. Weak-to-Strong Generalization: Eliciting Strong Capabilities With Weak Supervision. ArXiv:2312.09390 [cs].
[2] Zixiang Chen, Yihe Deng, Huizhuo Yuan, Kaixuan Ji, and Quanquan Gu. 2024. Self-Play Fine-Tuning Converts Weak Language Models to Strong Language Models. ArXiv:2401.01335 [cs, stat].
[3] Zhiqing Sun, Yikang Shen, Qinhong Zhou, Hongxin Zhang, Zhenfang Chen, David Cox, Yiming Yang, and Chuang Gan. 2023. Principle-Driven Self-Alignment of Language Models from Scratch with Minimal Human Supervision. ArXiv:2305.03047 [cs].
[4] Keming Lu, Bowen Yu, Chang Zhou, and Jingren Zhou. 2024. Large Language Models are Superpositions of All Characters: Attaining Arbitrary Role-play via Self-Alignment. ArXiv:2401.12474 [cs].
[5] Weizhe Yuan, Richard Yuanzhe Pang, Kyunghyun Cho, Sainbayar Sukhbaatar, Jing Xu, and Jason Weston. 2024. Self-Rewarding Language Models. ArXiv:2401.10020 [cs].