中国科学院软件研究所中文信息处理实验室多篇论文被ACL2025及ICML2025录用

近日,中国科学院软件研究所中文信息处理实验室 16 项研究成果被国际会议 ACL 2025 (主会长文 8 篇 + Findings长文 8 篇) 录用,1 项研究成果被 ICML 2025 录用。论文主题围绕大模型在预训练、后训练和推理阶段的知识机制和知识增强,具体工作介绍如下。
论文一:基于稀疏隐变量的RAG精准行为调控
论文标题:Sparse Latents Steer Retrieval-Augmented Generation
论文作者:Chunlei Xin, Shuheng Zhou, Huijia Zhu, Weiqiang Wang, Xuanang Chen, Xinyan Guan, Yaojie Lu, Hongyu Lin, Xianpei Han, Le Sun
合作单位:蚂蚁集团
发表会议:ACL 2025
录用类型:主会长文
论文简介:理解大型语言模型(LLM)在检索增强生成(RAG)系统中的行为机制对提升系统可靠性至关重要。本文利用稀疏自编码器(SAEs)揭示了控制RAG行为的稀疏可解释隐变量。通过对SAE激活模式的系统分析,我们发现了与两类核心RAG决策密切相关的特定隐变量:(1)外部上下文信息与内部记忆的优先级判定,以及(2)生成回复与拒绝回答的决策机制。干预实验表明,这些隐变量不仅能精确调控模型行为,还展现出跨实验场景的强泛化能力。内部机制分析进一步揭示,干预这些隐变量的激活程度可以重构负责复制粘贴行为的检索头的注意力模式,从而改变模型行为。本研究创新性地构建了基于稀疏隐变量的RAG行为调控框架,展示了其在无需架构修改的情况下实现精准行为引导的潜力。
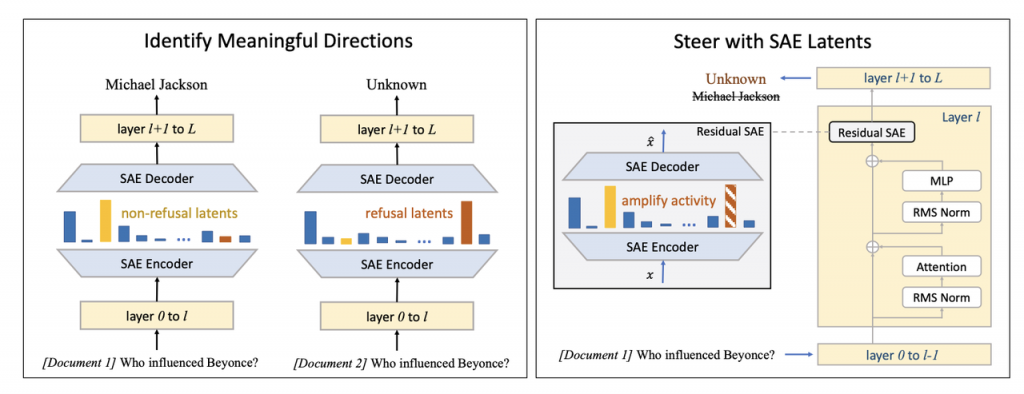
论文二:DeepSolution: 面向复杂工程的可靠性解决方案生成
论文标题:DeepSolution: Boosting Complex Engineering Solution Design via Tree-based Exploration and Bi-point Thinking
论文作者:Zhuoqun Li, Haiyang Yu, Xuanang Chen, Hongyu Lin, Yaojie Lu, Fei Huang, Xianpei Han, Yongbin Li, Le Sun
合作单位:阿里通义实验室
发表会议:ACL 2025
录用类型:主会长文
论文简介:为复杂工程需求设计解决方案在生产活动中至关重要。然而,目前检索增强生成(RAG)领域的工作尚未充分研究此类任务。为填补这一空白,我们提出了一个新的基准测试——SolutionBench,用于评估一个系统针对带有多项复杂约束的工程问题设计完整可行的解决方案的能力。为了进一步推动复杂工程需求下的解决方案设计,我们提出了一种新型系统——SolutionRAG,该系统利用基于树的探索和双点思维机制来生成可靠的解决方案。大量实验结果表明,SolutionRAG在SolutionBench上达到了当前最先进的性能(SOTA),展示了其在实际应用中提升复杂工程解决方案设计的自动化和可靠性的潜力。
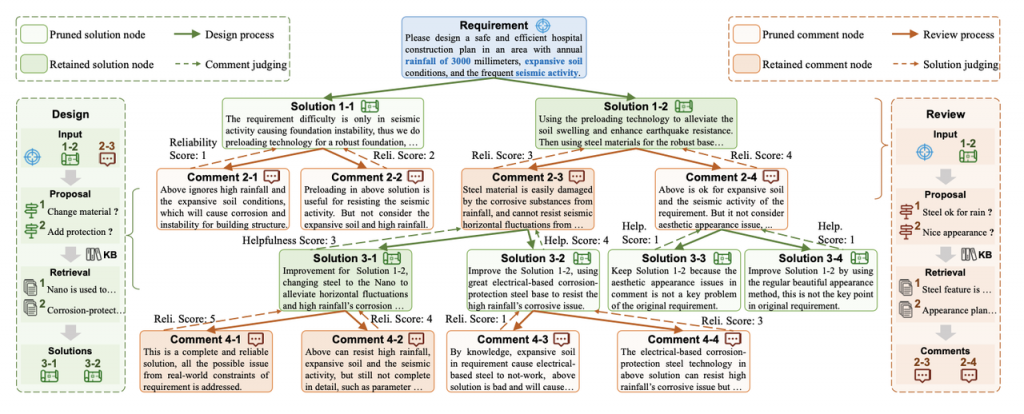
论文三:不止于死记硬背:基于推理的深度知识注入
论文标题:Memorizing is Not Enough: Deep Knowledge Injection Through Reasoning
论文作者:Ruoxi Xu, Yunjie Ji, Boxi Cao, Yaojie Lu, Hongyu Lin, Xianpei Han, Ben He, Yingfei Sun, Xiangang Li, Le Sun
合作单位:贝壳
发表会议:ACL 2025
录用类型:主会长文
论文简介:尽管大语言模型(LLM)在知识记忆与推理方面展现出卓越能力,但其静态特性导致模型知识难以适应现实世界动态演变及领域专精需求,凸显了高效知识注入方法的重要性。当前研究对知识注入深度的探索仍停留在表面层面,主要聚焦于知识记忆与检索等基础层面,缺乏系统性的层次划分与深度评估体系。本文提出包含记忆(Memorization)、检索(Retrieval)、推理(Reasoning)和关联(Association)的四层知识注入框架,通过层次化定义揭示了知识注入深度的递进关系。基于该框架,我们构建了基准DeepKnowledge,支持对新型知识、增量知识和更新知识三种知识类型的注入深度进行细粒度评估。通过多种知识注入场景的实验探索,系统揭示了LLM实现各层级知识注入的关键技术要素,并建立了知识注入层级与适配方法之间的映射关系。
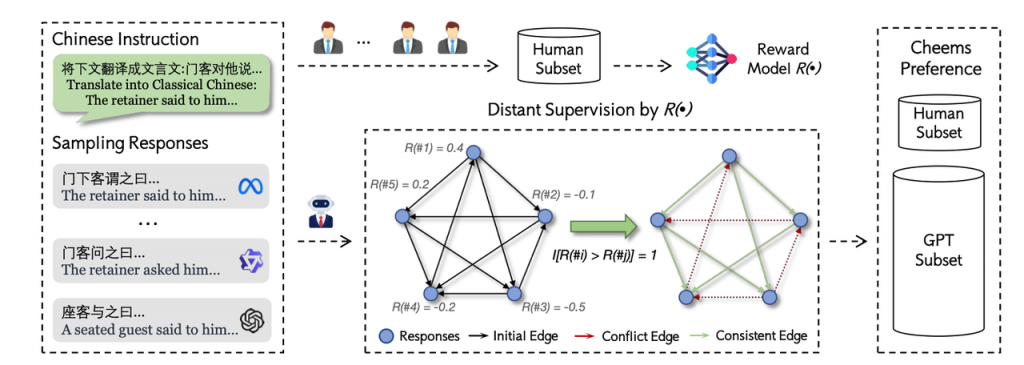
论文四:中文奖励模型实用指南:从入门到精通
论文标题:Cheems: A Practical Guidance for Building and Evaluating Chinese Reward Models from Scratch
论文作者:Xueru Wen, Jie Lou, Zichao Li, Yaojie Lu, Xing Yu, Yuqiu Ji, Guohai Xu, Hongyu Lin, Ben He, Xianpei Han, Le Sun, Debing Zhang
合作单位:小红书
发表会议:ACL 2025
录用类型:主会长文
论文简介:奖励模型是大语言模型对齐的关键组件。然而,现有研究主要聚焦于英文场景,且高度依赖合成数据,导致中文领域在偏好数据构建和模型评估方面仍存在显著不足。为填补这一空白,本文提出 CheemsBench,首个专注于中文偏好建模的人工标注奖励模型评估基准;同时构建了 CheemsPreference,一个涵盖多种语言风格与任务类型、通过人机协作标注的大规模中文偏好数据集,用于支持奖励模型的训练。基于 CheemsBench,本文系统评估了多种开源的判别式与生成式奖励模型,揭示了它们在中文偏好理解方面的局限性。进一步地,我们利用 CheemsPreference 训练了一个面向中文任务的奖励模型,在评估中表现出更优的对齐效果。
论文五:CRUXEval-X: 面向多语言代码的推理、理解和执行评估基准
论文标题:CRUXEVAL-X: A Benchmark for Multilingual Code Reasoning, Understanding and Execution
论文作者:Ruiyang Xu, Jialun CAO, Yaojie Lu, Ming Wen, Hongyu Lin, Xianpei Han, Ben He, Shing-Chi Cheung, Le Sun
合作单位:香港科技大学
发表会议:ACL 2025
录用类型:主会长文
论文简介:HumanEval 等代码基准被广泛用于评估大语言模型(LLM)的编程能力。然而,现有基准中存在显著的编程语言偏倚问题——超过 95% 的代码生成任务集中在 Python 上,导致模型在 Java、C/C++ 等其他语言中的能力尚未得到充分验证。此外,现有基准在任务类型上也存在偏倚,主要聚焦于代码生成,忽略了代码推理这一基础能力。代码推理包括根据输入推理输出,以及根据输出反推输入,这些能力对于程序理解与调试至关重要。然而,构建多语言、多任务类型的代码基准面临成本高、数据污染严重等挑战。一方面,人工构建高质量的跨语言测试集成本较高;另一方面,Leetcode 等编程平台上的题目可能在训练数据中已出现,影响评估公正性。为填补这一空白,我们提出了 CRUXEval-X,一个面向多语言代码推理的评测基准,涵盖 19 种编程语言,每种语言至少包含 600 个题目,总计超过 19,000 个测试任务。CRUXEval-X 的构建流程完全自动化,基于测试样例驱动,通过执行反馈进行迭代生成与语义修复。同时,我们设计了语言对之间的转换规则,用于跨越语言差异(例如动态类型与静态类型系统),实现高质量的跨语言代码迁移。我们使用 CRUXEval-X 对 24 个具有代表性的 LLM 进行了系统评估,揭示了不同编程语言之间的性能相关性。例如,TypeScript 与 JavaScript 之间呈现出高度正相关,而 Racket 与其他语言的相关性较低。更有意义的是,即便是仅在 Python 上训练的模型,在未见语言上仍可达到最高 34.4% 的 Pass@1,体现出大语言模型在代码任务中的跨语言泛化能力。

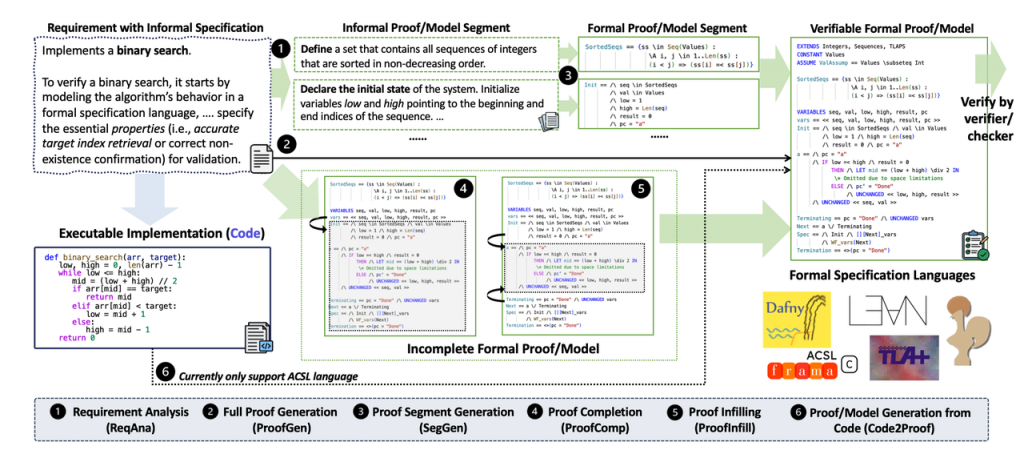
论文六:从自然语言到形式化语言:大语言模型的形式化验证能力评估
论文标题:From Informal to Formal – Incorporating and Evaluating LLMs on Natural Language Requirements to Verifiable Formal Proofs
论文作者:Jialun Cao, Yaojie Lu, Meiziniu Li, Haoyang Ma, Haokun Li, Mengda He, Cheng Wen, Le Sun, Hongyu Zhang, Shengchao Qin, Shing-Chi Cheung, Cong Tian
合作单位:香港科技大学、西安电子科技大学、重庆大学
发表会议:ACL 2025
录用类型:主会长文
论文简介:近年来,基于人工智能的形式化数学推理研究呈现出迅速发展的趋势。这些研究在国际数学奥林匹克(IMO)等数学竞赛中表现优异,并取得了显著进展。本文聚焦于形式推理的直接应用场景——形式化验证,并将其拆解为多个子任务,便于大模型建模。我们基于GPT-4o构建了涵盖五种形式化规范语言(Coq、Lean4、Dafny、ACSL和TLA+)的18,000对高质量指令-响应对,并对包括DeepSeek-R1在内的十个开源大语言模型进行了系统评估。基于这些数据,本文微调了多个7-8B的小模型,达到了与DeepSeek-R1-671B相当的性能。令人关注的是,我们发现,使用形式化数据进行微调不仅提升了验证能力,还增强了数学、推理和编程能力。相关模型已发布在 https://huggingface.co/fm-universe。
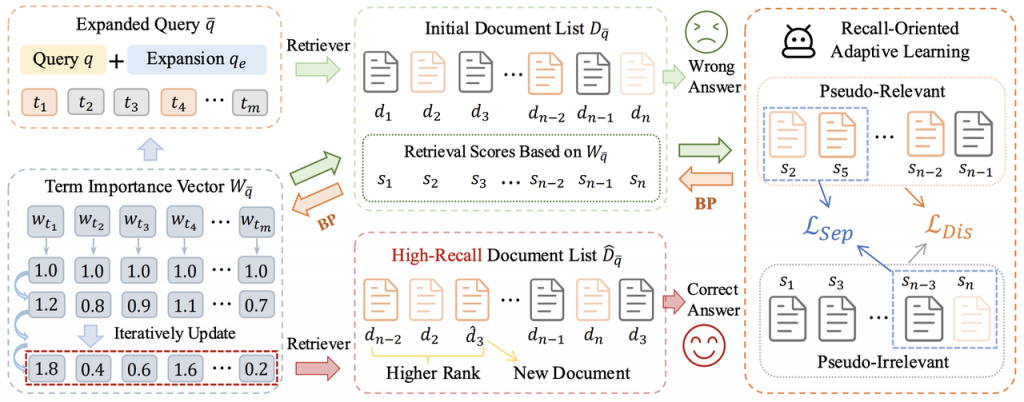
论文七:去芜存菁:大模型查询扩展的召回自适应学习
论文标题:Not All Terms Matter: Recall-Oriented Adaptive Learning for PLM-aided Query Expansion in Open-Domain Question Answering
论文作者:Xinran Chen, Ben He, Xuanang Chen, Le Sun
发表会议:ACL 2025
录用类型:主会长文
论文简介:本论文聚焦于开放域问答(Open-Domain Question Answering, ODQA)系统中的查询扩展(Query Expansion, QE)任务。当前许多利用预训练语言模型(PLM)进行查询扩展的方法在生成扩展术语时未能区分不同术语的重要性,导致检索效果不佳。为此,作者提出了一种新的方法——面向召回的自适应学习(Recall-oriented Adaptive Learning, ReAL)。ReAL通过一个基于相似度的判别模型对初始检索文档进行伪相关性分类,并结合两种定制的损失函数动态调整扩展术语的权重,从而优化查询表示和文档检索精度。实验在四个ODQA数据集(Natural Questions、TriviaQA、WebQuestions和CuratedTREC)和五种主流QE方法上进行,结果表明,ReAL显著提升了检索的召回率以及端到端问答系统的整体表现。该方法为提高PLM辅助的查询扩展策略提供了高效且实用的解决方案。
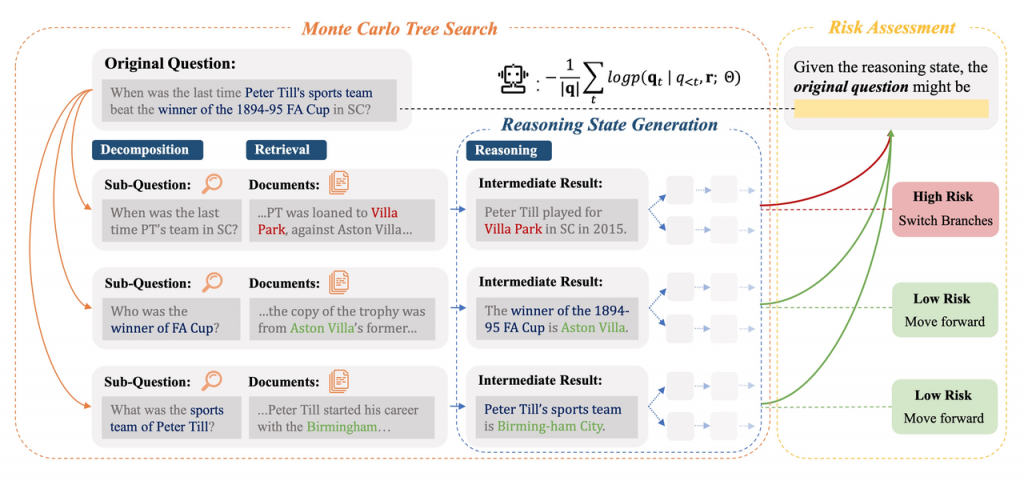
论文八:基于风险自适应搜索的大模型知识增强推理
论文标题:ARise: Towards Knowledge-Augmented Reasoning via Risk-Adaptive Search
论文作者:Yize Zhang†, Tianshu Wang†, Sirui Chen, Kun Wang, Xingyu Zeng, Hongyu Lin, Xianpei Han, Le Sun, Chaochao Lu‡
合作单位:商汤、上海 AI Lab
发表会议:ACL 2025
录用类型:主会长文
论文简介:大语言模型(LLMs)已展现出令人印象深刻的能力,并且通过缩放测试时计算来增强其推理能力正受到越来越多的关注。然而,它们在开放式、知识密集型、复杂推理场景中的应用仍然有限。现有推理导向的方法由于假设世界知识完备,难以泛化到开放场景;而知识增强推理(KAR)的方法则面临两大核心挑战:1) 错误传播,即早期步骤中的错误会在整个推理链中级联;2) 验证瓶颈,即在多分支决策过程中出现的探索与利用权衡的问题。为此,我们提出了一种新颖的知识增强推理框架 ARise,将中间推理状态的风险评估与动态检索增强生成(RAG)集成在蒙特卡洛树搜索范式中。该方法能够在维护多个假设分支的同时,有效构建和优化推理计划。实验结果表明,ARise 显著优于最先进的 KAR 方法(提升幅度高达23.10%),以及最新的配备 RAG 的深度推理模型(提升幅度高达25.37%)。
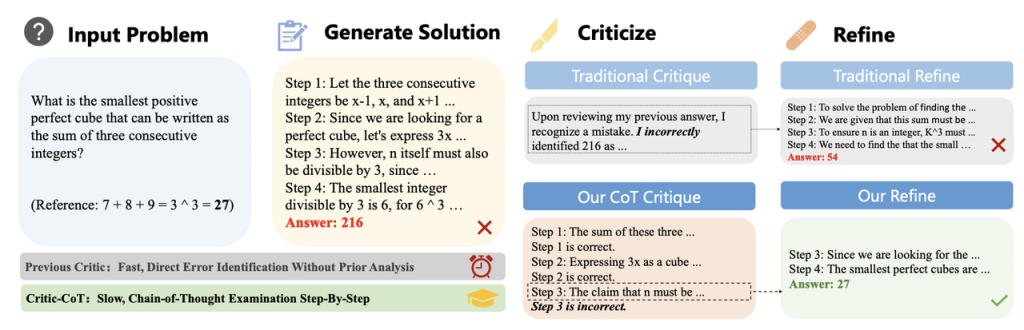
论文九:基于思维链评判的大语言模型推理能力提升
论文标题:Critic-CoT: Boosting the Reasoning Abilities of Large Language Model via Chain-of-Thought Critic
论文作者:Xin Zheng, Jie Lou, Boxi Cao, Xueru Wen, Yuqiu Ji, Hongyu Lin, Yaojie Lu, Xianpei Han, Debing Zhang, Le Sun
合作单位:小红书
发表会议:ACL 2025
录用类型:Findings 长文
论文简介:自我批判(self-critic)已成为增强大语言模型(LLM)推理能力的重要机制。然而,目前的方法主要依赖实例级反馈的简单提示词,往往只能产出启发式和浅层的批判信息,从而限制了模型的推理能力。为此,我们提出了一种新的框架 Critic-CoT,旨在推动大语言模型的批判范式实现从系统1到系统2的转变。具体的,通过逐步的思维链推理模式和无需人工标注的弱监督数据自动构建,Critic-CoT 使大语言模型能够进行慢速的、分析性的自我评判和改进,从而提高其推理能力。在 GSM8K 和 MATH 数据集上的实验表明,该方法增强的模型通过过滤错误求解或迭代改进,显著提升了任务求解的性能。此外,我们还研究了大语言模型内部评判能力与任务求解能力之间的内在关联,发现这两种能力可以相互增强。
论文十:面向幻觉消解的在线策略细粒度反馈自对齐
论文标题:On-Policy Self-Alignment with Fine-grained Knowledge Feedback for Hallucination Mitigation
论文作者:Xueru Wen, Jie Lou, Xinyu Lu, Yuqiu Ji, Xinyan Guan, Yaojie Lu, Hongyu Lin, Ben He, Xianpei Han, Debing Zhang, Le Sun
合作单位:小红书
发表会议:ACL 2025
录用类型:Findings 长文
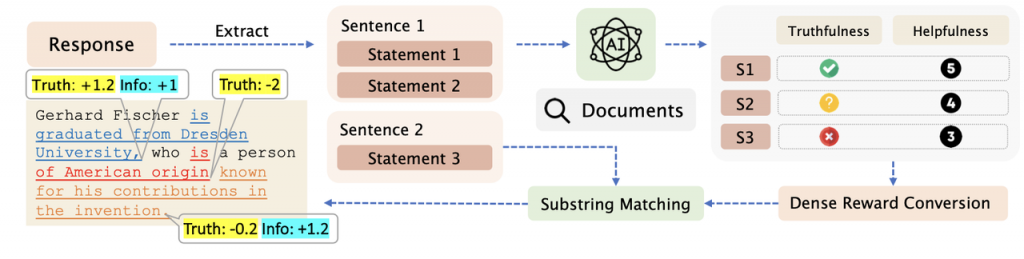
论文简介:大语言模型在生成回答时,常常会超出自身知识范围产生不实内容,即”幻觉”问题。以往研究通过微调模型来减少幻觉,但这些方法受限于非实时的样本采集策略和粗粒度的反馈信息。针对这些问题,这篇工作利用在线策略强化学习实现自我对齐。该方法的核心在于让模型自我评估生成内容,主动探索自身知识边界。具体来说,模型会将回答自动拆解为多个事实陈述,并借助外部知识库验证每条陈述的真实性和信息价值。这些精细的评估结果会转化为具体到每个词的奖励信号,从而实现无需人工的精准实时强化学习。
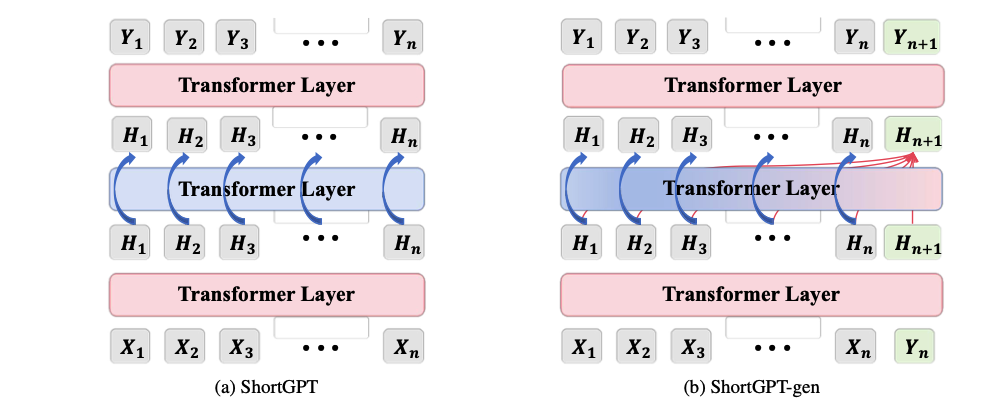
论文十一:ShortGPT:大模型的Layers比你预期的更冗余
论文标题:ShortGPT: Layers in Large Language Models are More Redundant Than You Expect
论文作者:Xin Men, Mingyu Xu, Qingyu Zhang, Qianhao Yuan, Bingning Wang, Hongyu Lin, Yaojie Lu, Xianpei Han, Weipeng Chen
合作单位:百川智能
发表会议:ACL 2025
录用类型:Findings 长文
论文简介:随着大语言模型的不断发展,其计算开销也大幅增加。在本研究中,我们发现了 LLM 各层之间存在明显的冗余,其中一些层对整体网络功能的贡献微乎其微。为了量化这一点,我们引入了BI(Block Influence)的指标,该指标根据各层输入和输出之间的相似性来衡量各层的重要性。基于对层冗余的观察,我们提出了针对不同类任务的层剪枝方法: 针对多选任务的 ShortGPT 和针对生成任务的 ShortGPT-gen。它们根据冗余层的 BI 分数对其进行剪枝。与之前的剪枝方法相比,我们的方法表现出更优越的性能。与更复杂的剪枝技术相比,通过简单的层剪枝就能获得更好的结果,这表明各层之间存在高度冗余。我们希望这项工作能为未来提高 LLM 效率的研究做出贡献。
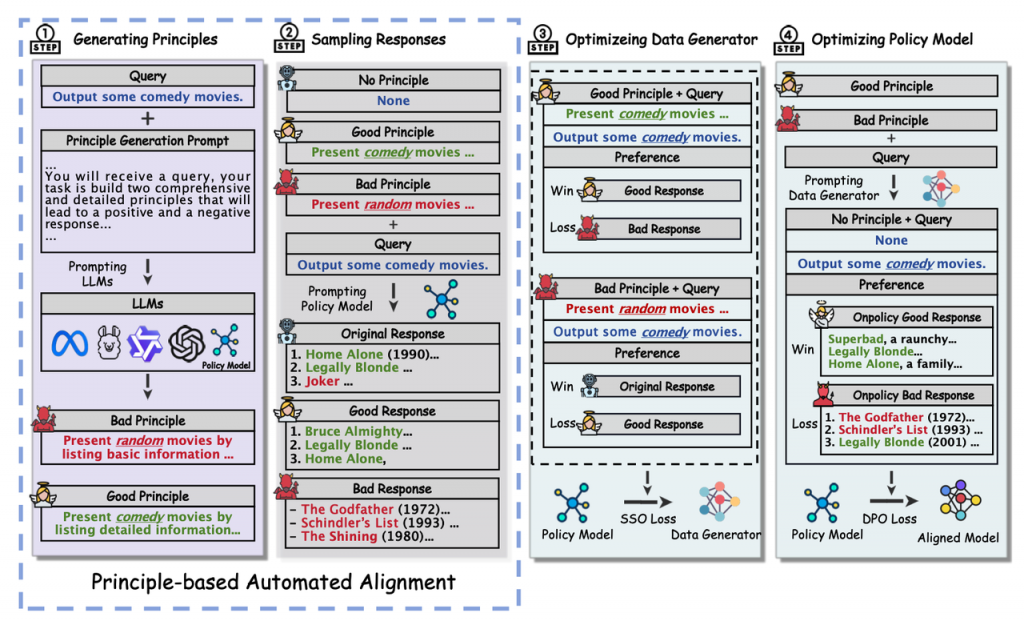
论文十二:基于自引导的大模型自主偏好优化
论文标题:Self-Steering Optimization: Autonomous Preference Optimization for Large Language Models
论文作者:Hao Xiang, Bowen Yu, Hongyu Lin, Keming Lu, Yaojie Lu, Xianpei Han, Ben He, Le Sun, Jingren Zhou, Junyang Lin
合作单位:通义千问
发表会议:ACL 2025
录用类型:Findings 长文
论文简介:有效的对齐关键在于高质量的偏好数据。近期研究主要关注自动化对齐,旨在开发无需大量人工干预的对齐系统。然而,以往研究主要集中在数据生成方法上,对质量控制机制关注不足,往往产生不准确且离线的数据,导致迭代优化中的效果不可预测。在本文中,我们提出自引导优化(Self-Steering Optimization,SSO),这是一种能够自主生成高质量偏好数据的算法,无需手动标注。SSO采用专门的优化目标,从策略模型本身构建数据生成器,用于生成准确且符合策略的数据。我们通过对Llama 3和Qwen 2两系列模型的全面实验证明了SSO的有效性。在多个基准测试中的评估表明,SSO在人类偏好对齐和奖励优化方面始终优于基线方法。进一步分析验证了SSO作为一个可扩展的偏好优化框架,有利于自动化对齐技术的进步。
论文十三:DiffLM:基于扩散语言模型的可控合成数据生成
论文标题:DiffLM: Controllable Synthetic Data Generation via Diffusion Language Models
论文作者:Ying Zhou, Xinyao Wang, Yulei Niu, Yaojie Shen, Lexin Tang, Fan Chen, Ben He, Le Sun, Longyin Wen
合作单位:字节跳动
发表会议:ACL 2025
录用类型:Findings 长文
论文简介:近年来,大语言模型(LLMs)在知识理解与文本生成方面取得了显著进展,推动了高质量合成数据生成在多个场景中的应用。然而,当前基于提示工程的生成方式面临显著挑战,尤其是在处理结构化数据(如表格、代码、工具调用)时,存在数据分布理解不足、输出多样性受限以及生成流程复杂等问题。为应对这些挑战,本文提出DiffLM,一种融合变分自编码器(VAE)与潜空间扩散建模的可控数据合成框架。DiffLM 通过构建独立于语言模型的潜空间来建模真实数据分布,并引入扩散过程提升潜向量的表达能力,从而实现与 LLM 解码过程的灵活解耦与高质量合成控制。具体而言,DiffLM 首先利用 VAE 捕捉真实数据的语义表示,再通过扩散模型学习高度保真的潜在分布,最后设计软提示机制将潜向量注入至 LLM 解码流程,实现可控高质量文本生成。实验在7个真实结构化数据集上进行,涵盖表格、代码与工具使用等任务,结果表明DiffLM在下游任务中可稳定提升2%–7%的性能,部分场景下甚至优于真实数据。消融实验进一步验证了各模块在整体系统中的有效性,展示了DiffLM在结构化合成数据生成中的鲁棒性与先进性。
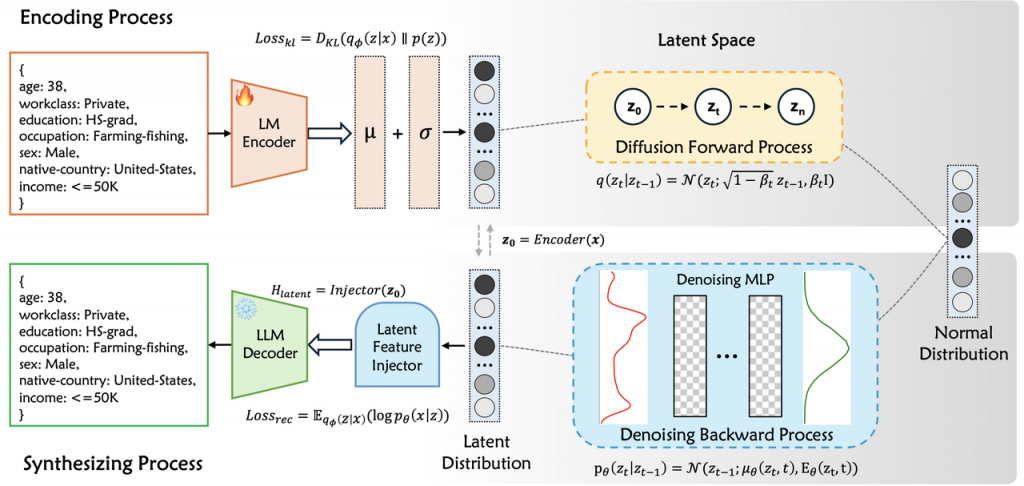
论文十四:基于大模型代码风格偏好适配的高效鲁棒调试方法
论文标题:Code-SPA: Style Preference Alignment to Large Language Models for Effective and Robust Code Debugging
论文作者:Tengfei Wen, Xuanang Chen, Ben He, Le Sun
发表会议:ACL 2025
录用类型:Findings 长文
论文简介:大语言模型(LLMs)在代码生成与调试任务中展现出卓越能力,但现实场景中的用户代码常存在低质量风格问题,包括结构混乱、风格偏离和缺陷测试用例等多种噪声。我们在八种扰动以及对应的混合扰动上进行了调试任务的鲁棒性测试,验证了低质量与风格偏移的代码会降低LLMs的调试性能。为此,我们提出Code-SPA方法,通过分析LLMs偏好的代码风格,对输入代码进行基于具体语法树(CST)的规范化转换和LLM辅助的风格校准,从而有效缓解代码风格噪声对调试的干扰。实验表明,Code-SPA在HumanEval、MBPP和EvalPlus数据集上显著提升了通用和专用LLM的调试性能,为代码风格鲁棒性研究提供了新思路。
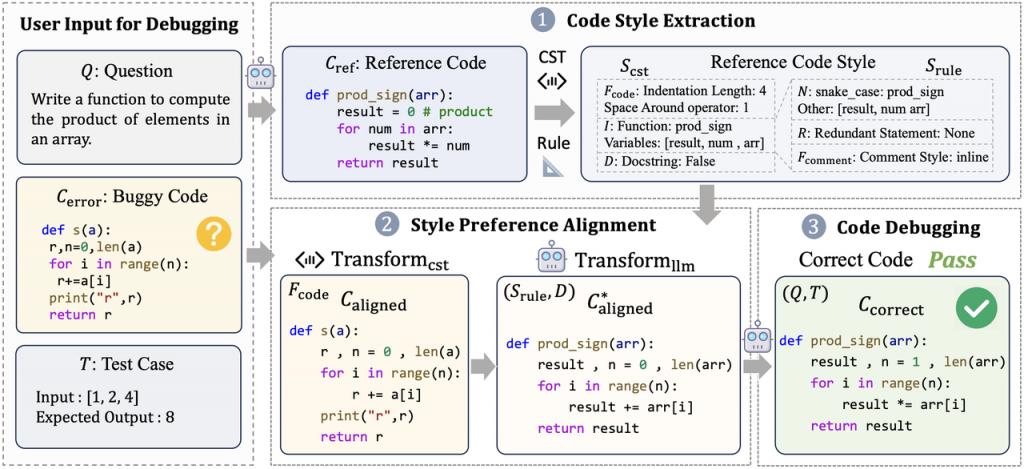
论文十五:大模型语言地图:大模型的内在语言谱系分析
论文标题:The Linguistic Connectivities Within Large Language Models
论文作者:Dan Wang, Boxi Cao, Ning Bian, Xuanang Chen, Yaojie Lu, Hongyu Lin, Jia Zheng, Le Sun, Shanshan Jiang, Bin Dong, Xianpei Han
合作单位:理光
发表会议:ACL 2025
录用类型:Findings 长文
论文简介:大语言模型在多种应用中表现出了卓越的多语言能力。然而,近期研究发现这些模型在不同语言之间的性能表现存在显著差异。深入理解这些差异背后的原因对于确保全球用户公平使用大语言模型至关重要。因此,本文系统地探究了大语言模型在27种不同语言的三种情境下的表现,并发现了一个在大语言模型内部存在“语言图谱”的现象。其中,语言之间的信息传播取决于其语言资源丰富度和语言家族谱系。具体来说,特定语言家族中资源丰富的语言展现了更高的知识一致性和信息传播能力,而资源较少或较为孤立的语言则往往处于边缘地位。该研究深入揭示了大语言模型跨语言行为的内在机制,突出了多语言环境中大语言模型的固有偏见,并强调了解决这些不平等的迫切需求。
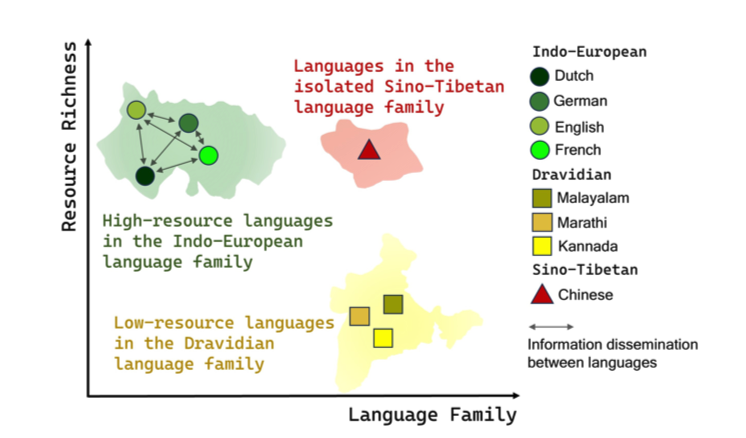
论文十六:READoc:面向真实文档结构化任务的统一基准
论文标题:READoc: A Unified Benchmark for Realistic Document Structured Extraction
论文作者:Zichao Li, Aizier Abulaiti, Yaojie Lu, Xuanang Chen, Jia Zheng, Hongyu Lin, Xianpei Han, Shanshan Jiang, Bin Dong, Le Sun
合作单位:理光
发表会议:ACL 2025
录用类型:Findings 长文
论文简介:文档结构化提取(Document Structured Extraction,DSE)的目标是从原始文档中提取结构化内容。尽管已经出现了许多DSE系统,但对它们的统一评估仍然不足,这极大地阻碍了该领域的发展。这一问题主要归因于现有的基准测试范式,它们呈现出分散和局部化的特征。为了全面评估DSE系统,我们提出了一个名为READoc的新基准测试,它将DSE定义为将非结构化的PDF转换为语义丰富的Markdown的现实任务。READoc数据集来源于arXiv、GitHub和Zenodo上的3,576份多样化的真实世界文档。此外,我们开发了一个包含标准化(Standardization)、分段(Segmentation)和评分(Scoring)模块的DSE评估套件(Evaluation Suite),以对最先进的DSE方法进行统一评估。通过评估一系列的流水线工具、专家视觉模型和通用视觉语言模型(VLMS),我们首次识别了当前工作与统一的、现实的DSE目标之间的差距。我们期望READoc能够推动未来DSE领域的研究,促进更全面和实用的解决方案的出现。
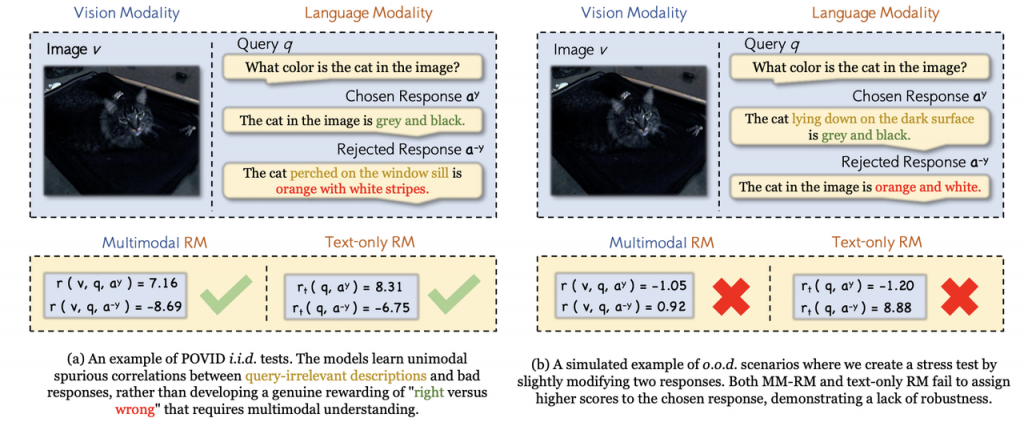
论文十七:知微见著:揭开单模态虚假关联,构建可泛化多模态奖励模型
论文标题:The Devil Is in the Details: Tackling Unimodal Spurious Correlations for Generalizable Multimodal Reward Models
论文作者:Zichao Li, Xueru Wen, Jie Lou, Yuqiu Ji, Yaojie Lu, Xianpei Han, Debing Zhang, Le Sun
合作单位:小红书
发表会议:ICML 2025
录用类型:主会长文
论文简介:在大语言模型(LLMs)越来越多地处理多模态数据的背景下,多模态奖励模型(MM-RMs)在将 LLMs 与人类偏好对齐方面发挥着至关重要的作用。然而,现有的 MM-RMs 在泛化到分布外场景时面临挑战,主要原因是它们依赖于单模态虚假关联,尤其是独立同分布的训练数据中的纯文本捷径,这阻碍了它们学习真正的多模态奖励函数。为了解决这一问题,我们提出了一种 Shortcut-aware MM-RM 学习算法。该算法通过动态重新加权训练样本,引导模型转向更深入的多模态理解,并减少对单模态捷径的依赖。通过引入一个纯文本奖励模型作为捷径代理,算法能够识别出单模态捷径失效的实例,并通过动态样本加权来强调多模态理解的重要性。该算法显著提高了模型在跨分布转移中的泛化能力,并且在下游任务中展现出更强的性能和可扩展性,证明了其鲁棒性和实际应用价值。