中国科学院软件研究所中文信息处理实验室多项研究成果被期刊 TOIS 和国际会议 MLSys、ICLR 等录用
近日,中国科学院软件研究所中文信息处理实验室(https://www.icip.org.cn)多项研究成果被顶级期刊 TOIS 和国际会议 MLSys、ICLR 、ICSE、AAAI、EACL录用。论文主题聚焦大模型智能体的知识机制与增强,涵盖知识获取及其影响、对齐与评估,以及系统推理与应用。具体工作介绍如下。
论文一:破解沉默螺旋:大模型时代基于效用驱动的均衡信息检索优化框架
论文标题:Breaking the Spiral: A Utility-Driven Optimization Framework for Balanced Information Retrieval in the LLM Era
论文作者:Xiaoyang Chen, Ben He, Hongyu Lin, Xianpei Han, Tianshu Wang, Boxi Cao, Le Sun, Yingfei Sun
录用期刊:TOIS
录用类型:期刊长文
论文链接:https://dl.acm.org/doi/10.1145/3788865
论文简介:大语言模型(LLMs)和检索增强生成(RAG)系统的广泛应用正在重塑信息检索的格局,我们之前的工作揭示了大模型生成内容对检索生态的沉默螺旋(Spiral of Silence)效应(ACL 24)。该效应表现为随着特定类型的内容占据主导地位,多样化的信息被边缘化,从而导致信息生态系统的同质化。随着系统中 LLM 生成文本的增加,检索系统表现出更倾向于检索这些文本的趋势。这种趋势进而降低了人类生成内容的可见性,削弱了多样性,传播了错误,并导致检索性能显著下降。为了应对这些挑战,本文提出了一种效用驱动的多目标优化(Utility-Driven Multi-Objective Optimization, UMO)框架,以有效缓解“沉默螺旋”现象。该框架采用两阶段方法:1. 优化阶段:利用 NSGA-II 算法推导多目标的最佳偏好权重;2. 记忆阶段:将这些权重直接集成到检索向量空间中,无需进行额外的模型再训练。实验结果表明,该框架保持了稳定的检索效能,提高了人类生成内容的检索比例,降低了 LLM 生成文本的过度影响,并保护了信息多样性,从而有效地缓解了“沉默螺旋”。
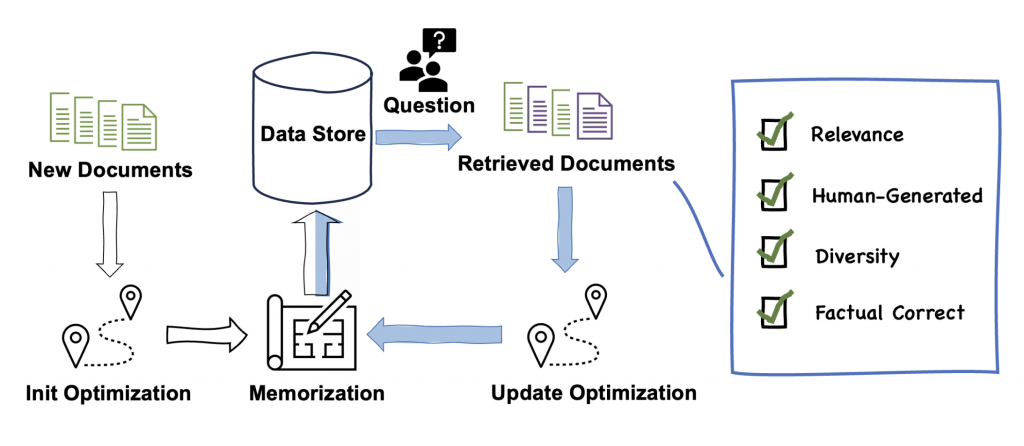
论文二:FlashAgents:通过流式预填充重叠加速多智能体大模型推理
论文标题:FlashAgents: Accelerating Multi-Agent LLM Systems via Streaming Prefill Overlap
论文作者:Taosong Fang, Zhen Zheng, Zhengzhao Ma, Yaojie Lu, Hongyu Lin, Xianpei Han, Le Sun
合作单位:微软
发表会议:MLSys 2026
录用类型:主会长文
论文简介:随着大语言模型(LLMs)在多智能体系统中的广泛应用,智能体间的串行交互成为制约系统响应速度的关键瓶颈。传统推理系统要求下游智能体等待上游完成全部生成后才能开始处理,导致大量计算资源闲置。为解决这一问题,我们提出了 FlashAgents 框架,通过流式增量预填充(Inter-Agent Streaming with Incremental Prefill)技术实现上游解码与下游预填充的并行执行,有效隐藏智能体间的切换延迟。同时,基于基数树的轮内前缀缓存机制可在并发场景下自动检测并消除共享上下文的重复计算。在 SGLang 推理引擎上的实验结果表明,FlashAgents 在受控双智能体基准测试和真实多智能体工作流中实现了显著的端到端延迟降低,展现了其在多样化模型和交互模式下的稳定性能提升。
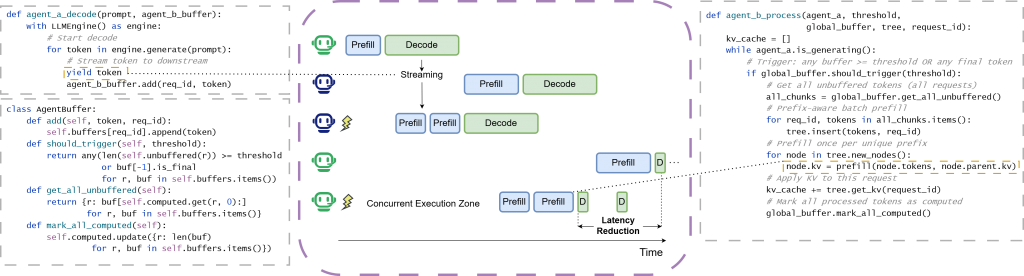
论文三:Auto-RT: 面向大语言模型红队评测的自动越狱策略搜索
论文标题:Auto-RT: Automatic Jailbreak Strategy Exploration for Red-Teaming Large Language Models
论文作者:Yanjiang Liu, Shuheng Zhou, Yaojie Lu, Huijia Zhu, Weiqiang Wang, Hongyu Lin, Ben He, Xianpei Han, Le Sun
合作单位:蚂蚁集团
发表会议:ICLR 2026
录用类型:主会长文
论文链接:https://arxiv.org/abs/2501.01830
论文简介:自动红队评测已成为识别大语言模型安全漏洞的关键手段,但现有方法大多依赖固定的攻击模版,且聚焦于单一的高严重性缺陷,限制了其对不断进化的模型防御机制的适应能力。由于缺乏灵活性,如何摆脱对固定攻击模版的依赖以检测复杂且高可利用性的漏洞仍是当前自动红队评测面临的挑战。为此我们提出了Auto-RT,这一基于强化学习的自动越狱策略搜索框架,旨在发现多样化且高效的攻击提示词。通过将攻击生成过程建模为多奖励过程的马尔可夫过程,Auot-RT能够根据目标模型的反馈动态调整策略搜索方向,在探索新的攻击路径与挖掘高可利用性漏洞之间实现平衡。实验结果表明Auto-RT在攻击成功率上由于现有策略攻击基准方法,证明了其在自动化挖掘模型深层次安全漏洞方面的有效性。
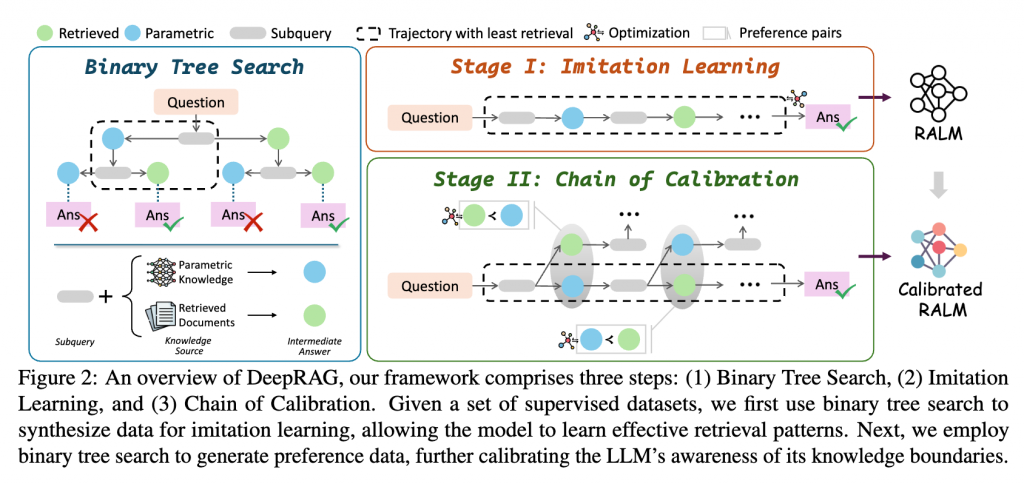
论文四:DeepRAG:让大语言模型逐步思考、逐步检索
论文标题:DeepRAG: Thinking to Retrieve Step by Step for Large Language Models
论文作者:Xinyan Guan, Jiali Zeng, Fandong Meng, Chunlei Xin, Yaojie Lu, Hongyu Lin, Xianpei Han, Le Sun, Jie Zhou
合作单位:微信
发表会议: ICLR 2026
录用类型:主会长文
论文链接:https://arxiv.org/abs/2502.01142
论文简介:大型语言模型展现出了卓越的推理能力,但由于其参数化知识在时效性、准确性和全面性上的局限,导致的严重事实性幻觉限制了其实际应用。与此同时,由于任务分解效率低下和检索冗余,如何将推理能力有效融合到检索增强生成中仍面临挑战,这些问题往往会引入噪声并降低回答质量。我们提出了 DeepRAG,这是一个将检索增强推理建模为马尔可夫决策过程的框架,从而实现了合理且自适应的检索。通过对查询进行迭代分解,DeepRAG 能够动态地决定在每一步是检索外部知识还是依赖自身的参数推理。实验结果表明,DeepRAG 提高了检索效率,并将回答准确率提升了 25.41%,证明了其在增强检索增强推理方面的有效性。
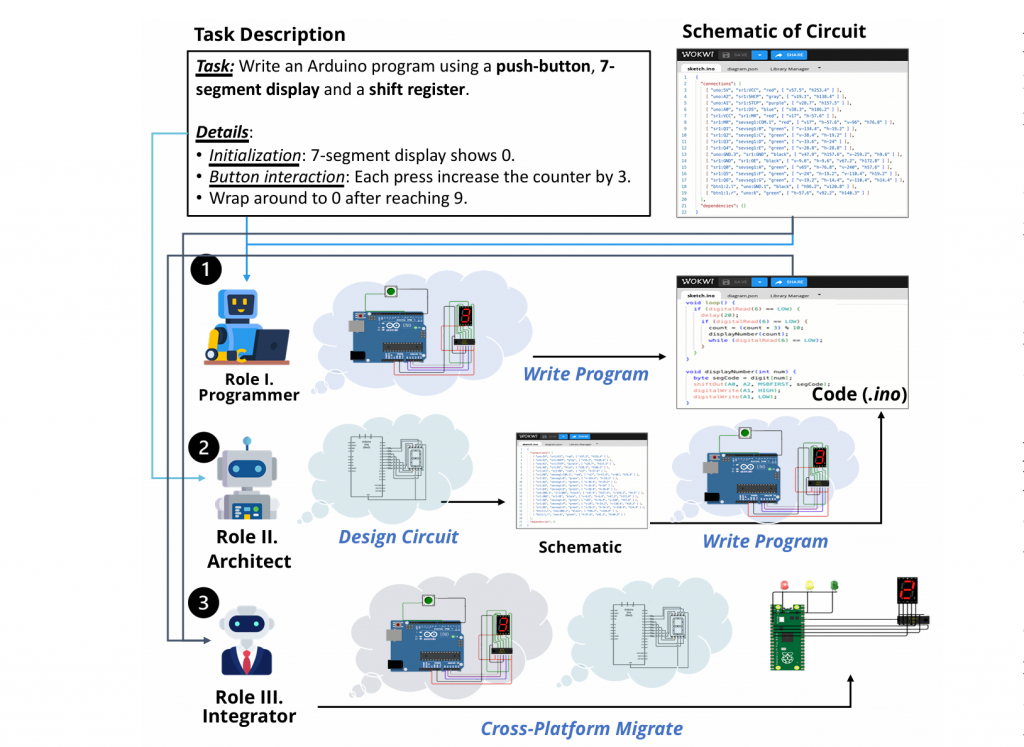
论文五:EmbedAgent:面向嵌入式系统开发的大语言模型基准评测
论文标题:EmbedAgent: Benchmarking Large Language Models in Embedded System Development
论文作者:Ruiyang Xu*, Jialun Cao*, Mingyuan Wu, Wenliang Zhong, Yaojie Lu, Ben He, Xianpei Han, Shing-Chi Cheung, Le Sun
合作单位:香港科技大学、鹏城实验室
发表会议:ICSE 2026
录用类型:主会长文
论文链接:https://arxiv.org/pdf/2506.11003
论文简介:本工作系统性地研究了大语言模型在嵌入式系统开发场景中的能力与局限。不同于现有主要聚焦通用软件工程或纯代码生成的评测基准,我们关注嵌入式系统这一连接数字计算与物理世界的关键应用场景,涵盖程序编写、电路设计以及跨硬件平台迁移等核心任务。为此,我们提出 EmbedAgent 这一多角色评测范式,通过模拟嵌入式程序员、系统架构师和系统集成者三种真实开发角色,对模型在多阶段、硬件感知任务中的表现进行端到端评估。基于该范式,我们构建了综合性基准 EmbedBench,并设计了一套基于虚拟硬件仿真的自动化评测流水线,实现了可扩展且可复现的评测过程。通过对多种主流大语言模型的系统实验与分析,我们揭示了当前模型在嵌入式系统开发中的典型失败模式,并探索了提升模型在该领域表现的有效方向。
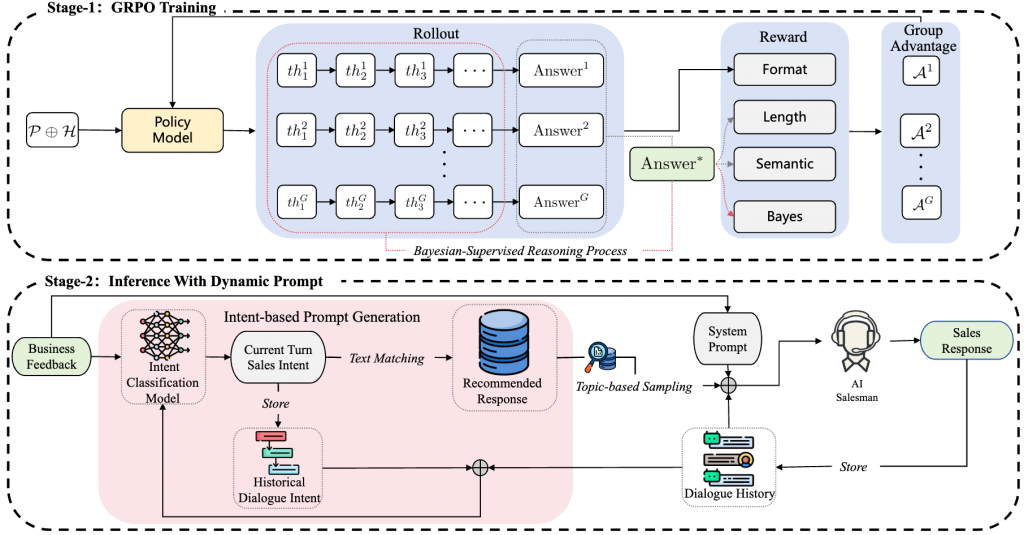
论文六:AI-Salesman:迈向可靠的大语言模型驱动电话营销
论文标题:AI-Salesman: Towards Reliable Large Language Model Driven Telemarketing
论文作者:Qingyu Zhang*, Chunlei Xin*, Xuanang Chen, Yaojie Lu, Hongyu Lin, Xianpei Han, Le Sun, Qing Ye, Qianlong Xie, Xingxing Wang
合作单位:美团
发表会议:AAAI 2026
录用类型:主会长文
论文链接:https://arxiv.org/abs/2511.12133
论文简介:目标驱动型说服性对话(如电话营销等应用场景)需要复杂的多轮规划与严格的事实准确性,这对当前最先进的大型语言模型(LLMs)仍构成重大挑战。任务特异性数据的匮乏常限制既有研究,而直接应用LLM则存在策略脆弱性和事实幻觉问题。本文首先构建并开源TeleSalesCorpus——该领域首个基于真实场景的对话数据集。随后提出AI-Salesman框架,其采用双阶段架构,在训练阶段采用贝叶斯监督强化学习算法,从噪声对话中学习稳健销售策略。推理阶段引入动态大纲引导智能体(DOGA),通过预构建脚本库提供动态逐轮策略指导。同时设计综合评估框架,将关键销售技能的精细化指标与“LLM-as-Judge”范式相结合。实验结果表明,我们提出的AI-Salesman框架在自动指标和人类评估中均显著优于基线模型,展现出其在复杂说服场景中的卓越效能。
论文七:问题重要吗?大语言模型评测中答案偏置的归因分析
论文标题:Does Question Really Matter? The Attribution of Answer Bias in LLM Evaluation
论文作者:Boxi Cao, Ruotong Pan, Hongyu Lin, Xianpei Han, Le Sun
发表会议:AAAI 2026
录用类型:主会长文
论文简介:多项选择问答(MCQA)作为一种大语言模型评估中最常使用的任务形式之一,近年来受到广泛关注。然而,已有大量证据表明,当前 MCQA 基准的评测结果普遍受到显著的答案偏置影响,从而严重削弱了评估结论的可靠性。具体而言,即便在完全移除题干信息的情况下,许多大模型依然能够取得远高于随机选择的表现。为此,我们对答案偏置的成因进行了系统性研究,并发现:数据污染程度与答案偏置的严重性之间呈现高度相关性;相比之下,选项位置以及答案的流行度对偏置的影响相对较小。在此基础上,我们进一步提出 OPD,这是一种无需访问模型内部训练数据即可用于污染检测与数据集去偏的简洁而有效的工具。我们的研究发现与提出的方法为未来构建可信的大模型评测协议提供了重要参考。

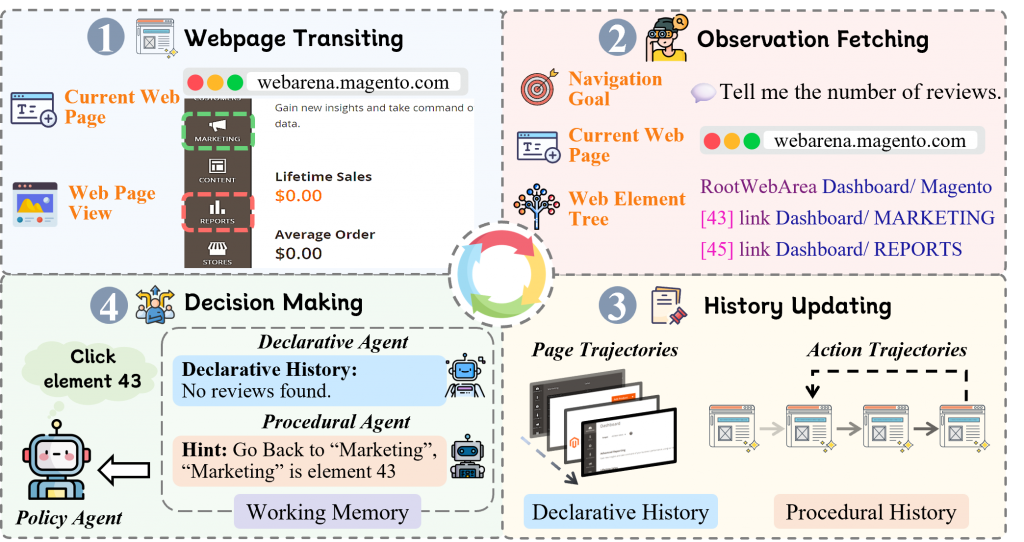
论文八:拨云见日:基于多智能体协作的网络空间自主探索
论文标题:Navigating the Infinite Dynamic Web Space: Effective In-Context Exploration via Cognitive Multi-Agent Collaboration
论文作者:Guozhao Mo, Yanjiang Liu, Yafei Shi, Jiawei Chen, Yang Li, Yaojie Lu, Hongyu Lin, Ben He, Le Sun, Bo Zheng, Xianpei Han
合作单位:网商银行
发表会议:EACL 2026
录用类型:主会长文
论文简介:动态网页导航由于决策空间近乎无限以及网络环境的持续变化而极具挑战性。现有方法多依赖贪心策略或价值估计,难以实现有效回溯。为此,本文提出 HintNavigator,一种基于认知的多智能体协作框架,通过 In-Context Exploration(ICE) 提升对网络空间的探索能力。受人类认知规划过程的启发,我们将交互历史划分为声明式历史(环境观测)与过程式历史(动作轨迹),以增强对历史信息的反思与利用能力。上述双历史流通过专门设计的认知智能体进行动态整合,在工作记忆巩固机制的引导下,实现高效的自主回溯。实验结果表明,HintNavigator 在 WebArena 测试中取得了开源LLM智能体中的最优性能,展现了双历史流的有效性。
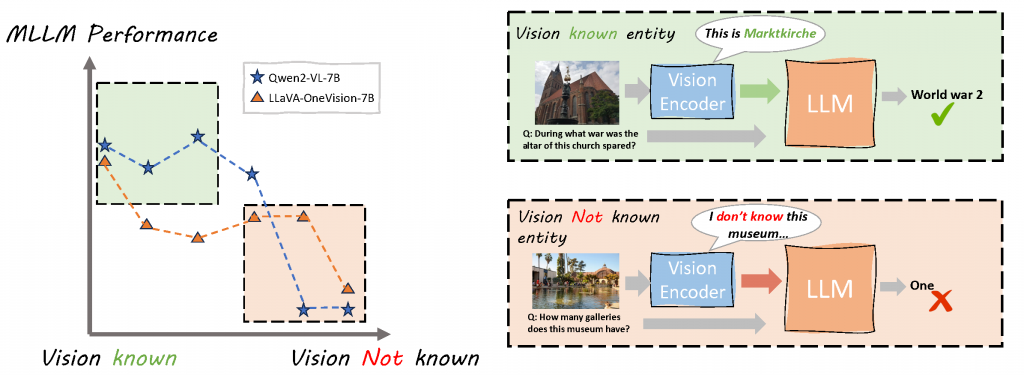
论文九:从度量到注入:视觉编码器先验知识对多模态大模型的影响分析
论文标题:Expanding the Boundaries of Vision Prior Knowledge in Multi-modal Large Language Models
论文作者:Qiao Liang*, Yanjiang Liu*, Weixiang Zhou, Ben He, Yaojie Lu, Hongyu Lin, Jia Zheng, Xianpei Han, Le Sun, Yingfei Sun
发表会议:EACL 2026
录用类型:主会长文
论文链接:https://arxiv.org/abs/2503.18034
论文简介:视觉编码器的先验知识是否会限制多模态大语言模型(MLLMs)的能力边界?尽管现有研究普遍将 MLLMs 视为端到端训练的统一系统,但视觉编码器先验知识对 MLLMs 的影响却较少被深入探讨。本文提出一种新颖指标Rank_e,用于量化视觉编码器先验知识。基于该指标的分析表明,视觉编码器的先验知识与 MLLM 整体性能呈显著正相关。进一步研究发现,仅依赖端到端的视觉问答数据进行领域微调往往效果有限,尤其对于视觉先验知识本身较为匮乏的实体类别。针对这一问题,我们提出 VisPRE(Vision Prior Remediation)框架,在视觉编码器层面注入领域先验知识。实验结果表明,增强视觉编码器的先验知识能够显著提升 MLLMs 的视觉理解能力,尤其是在涉及罕见视觉实体的场景中。